
Aligning LLMs to User Preference
Published:
Table of Contents:
- Why LLM Alignment
- Reinforcement learning from human feedback
- Direct Preference Optimization
- Kahneman-Tversky Optimization
- Survey studies
- Miscellaneous
0. Why LLM Alignment?
The main goal is ensuring the LLMs behave in ways that are helpful, safe, and aligned with human values and ethics. Another essential factor is that most users of domain-specific LLMs e.g. subject-matter expert, expect the LLM to follow the pattern in their specific domains.
1. Reinforcement learning from human feedback (RLHF)
Reinforcement learning provides an intrinsic solution to match the LLM behaviors to human preference by introducing an additional reward model.
The main steps of RLHF are:
- Pre-training a language model (LM)
- Using human feedback data to train a reward model (RM)
- Fine-tuning the policy model utilizing the reward model with reinforcement learning
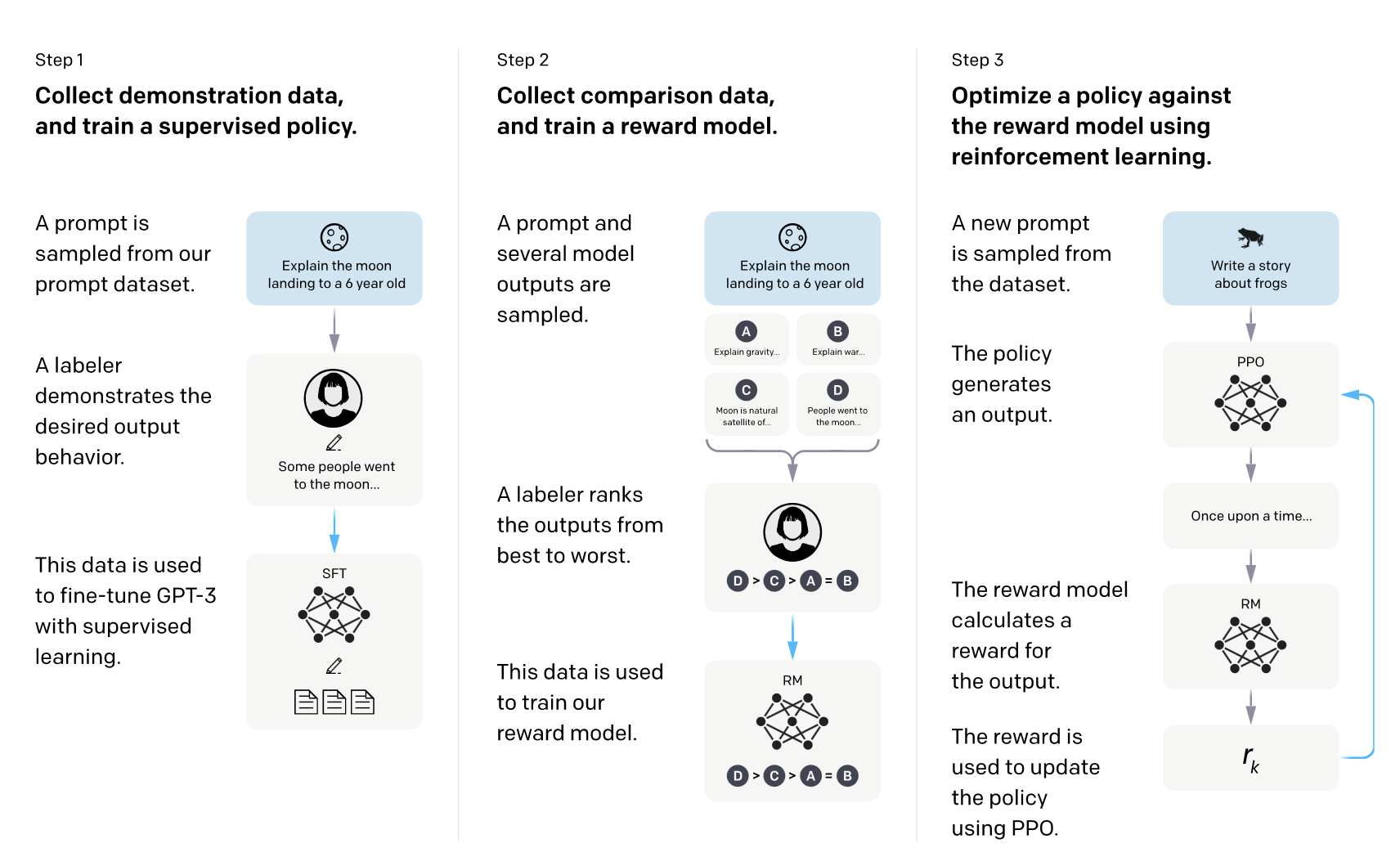 Image from Training language models to follow instructions with human feedback
Image from Training language models to follow instructions with human feedback
The pre-training of a language model are typically expensive and infeasible for most developers, but there are many open-sourced models available as a starting point.
Then, with a pre-trained model, one needs to have an approach to adjust the model to reflect the human preference, which immediately introduce two problems:
- How do we evalaute the human preference?
- How do we update the model to make the generated content to fit the huma preference?
The most obvious solution to the first question is to have a group of human to annotate/rank their preference on the response for the same prompt. But one may soon realize that this approach is not scalable since there are unlimited prompt-response combinations and it is even impossible to create a good sampling.
Here the trick comes in: we can train a standalone reward model (RM) to work as a proxy for real human preference. This new RM can be basically anything that generates a scalar reward to simulate human preference. Given a dataset of prompt-generattion with human annotation/ranking, the RM can learn how human may think about the generated outputs and work as grader to decide the score of a generated text. Mathematically, the reward model is gained by minimize the loss:
\[loss(\theta) = − \frac{1}{K \choose 2}\rm I\!E_{(x,y_w ,y_l)∼D} [\log (σ (r_\theta (x, y_w) − r_\theta (x, y_l)))]\]where $r_\theta (x, y)$ is the scalar output of the reward model for prompt $x$ and completion $y$ with parameters $θ$, $y_w$ is the preferred completion out of the pair of $y_w$ and $y_l$, and $D$ is the dataset of human comparisons
Now we have a hard-working annotator to tell the LLM how good/bad a completion is, we can jump to the second question. It is actually straight forward to make the optimization target as maximizing the following term:
\[E_{x∈D,y∈π_θ} [r_ϕ(x, y)] − βD_{KL}(π_θ (y|x)∥π_{ref}(y|x))\]which is the mixing of score from reward model and (per-token) KL divergence penalty between reference model and new policy model considering the reward should be high while the completion should not be too different from reference to avoid preformance regression. This model is referred as “PPO” by its inventors.
So far, everything seems to be good and case closed…or not?
While we are saying the reward model can work as proxy of human preference, it may only play a trick on the human-annotated dataset but failed to generalized. In practice, the performance of RLHF with PPO can be unstable and inconsistency (detailed discussion can be found in [2] ), as the reward model itself is not properly aligned with real human preference.
Meanwhile, the PPO approach is complex with multiple steps and inefficient in economics as fine-grained ranking annotation dataset is required.
2. Direct Preference Optimization (DPO)
Given the flaws in the PPO-based RLHF, clear and lazy researcher are looking for a short cut from human preeference feedback to the policy fine-tuning by estimating the human preference on the LM completions with the Bradley-Terry model using the probabilities of each completion are selected.
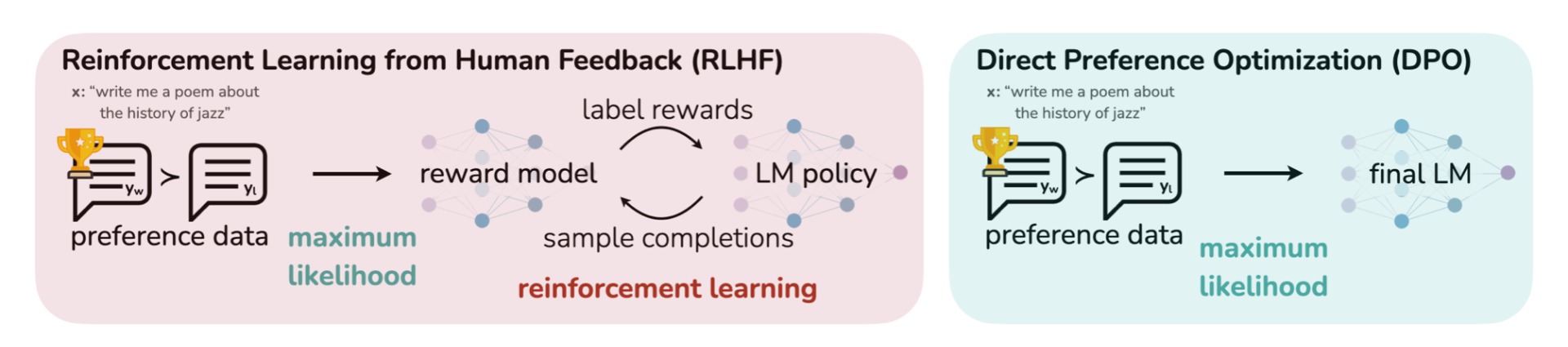 Image from Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Image from Direct Preference Optimization: Your Language Model is Secretly a Reward Model
And the fine-tunig of policy model is converted as an optimization problem to minimize the DPO loss:
\[\cal L_{\rm{DPO}}(π_θ ; π_{ref}) = −\rm I\!E_{(x,y_w ,y_l)∼D}[ \log σ(β \log \frac{π_θ (y_w | x)}{π_{ref}(y_w | x)} − β \log \frac{π_θ (y_l | x)}{π_{ref}(y_l | x)})]\]Comparing to the heavy annotation required in the PPO-based RLHF, DPO only requires A vs B preference choice from user which make it possible to collect the real user preference online.
However, A versus B comparison requires a pair of completions for the user to select from. Double computing resource is required and the “preference” is quite questionable based on my own experience as user. In many cases, there is no strong bias on either of them but make accidental/random selection.
A more reliable and easy-to-get feedback from user is thumbs-up/thumbs-down which indicates human judgement on the value of LM completion. And now it is time to think about how we can use those un-paired preference notions.
3. Kahneman-Tversky Optimization (KTO)
Kahneman & Tversky’s prospect theory has pointed out that humans’ decision making do not maximize the expected value when facing with an uncertain event. Instead of maximizing the reward scores of LM completion outputs, KTO is focusing on the human utility. 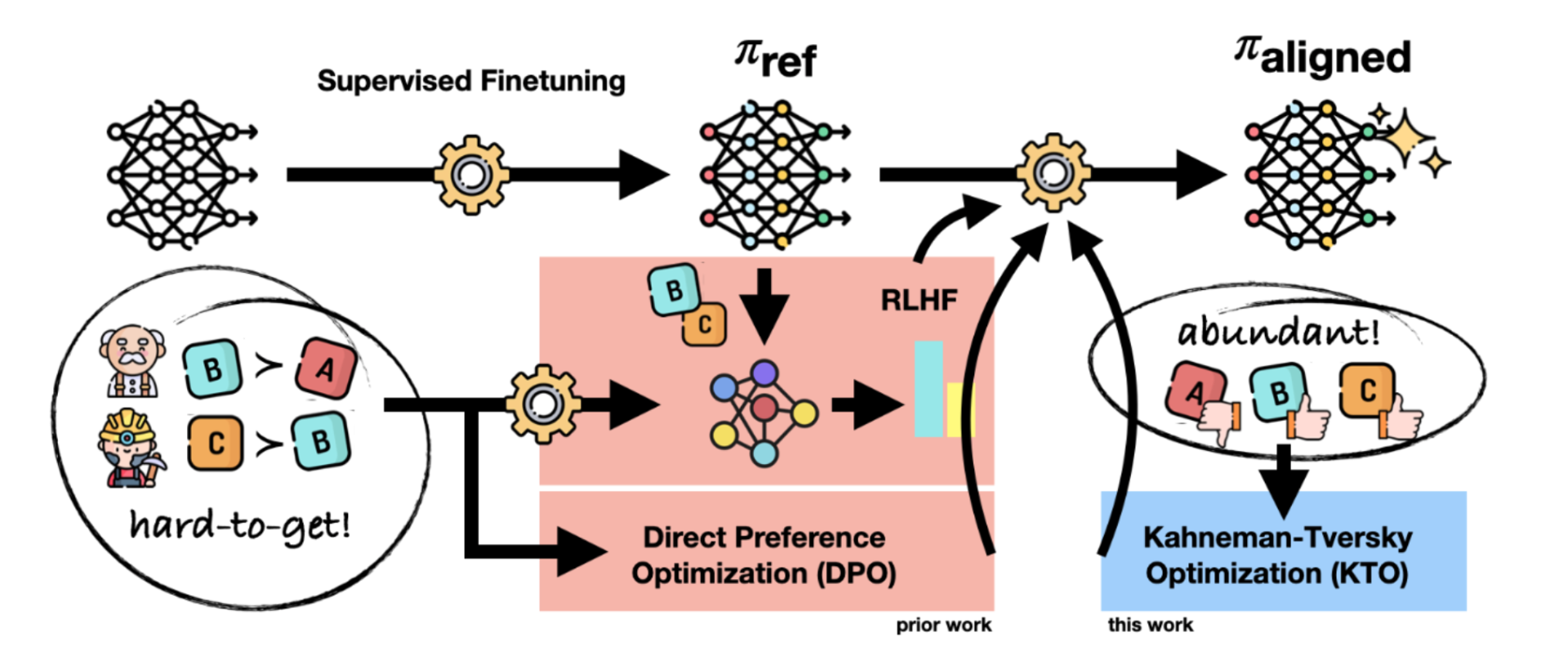 Image from KTO: Model Alignment as Prospect Theoretic Optimization
Image from KTO: Model Alignment as Prospect Theoretic Optimization
The modified loss funcntion is then:
\[L_{\rm{KTO}}(π_θ , π_{ref}) = E_{x,y∼D} [w(y)(1 − v_{\rm{KTO}}(x, y; β))]\]where
\[r_{\rm{KTO}}(x, y) = β \log \frac{π_θ (y\|x)}{π_{ref}(y\|x)}\] \[z_{ref} = \rm I\!E_{x^{′}∼D} [β\rm{KL}(π_θ (y^{′}\|x^{′})∥π_{ref}(y^{′}\|x^{′}))]\] \[v_{\rm{KTO}}(x, y; β) = \begin{cases} σ(r_{\rm{KTO}}(x, y) − z_{ref}) \text{ if } y ∼ y_{desirable}|x \\ σ(z_{ref} − r_{\rm{KTO}}(x, y)) \text{ if } y ∼ y_{undesirable}|x \end{cases}\] \[w(y) = \begin{cases} \lambda_D \text{ if } y ∼ y_{desirable}|x \\ \lambda_U \text { if } y ∼ y_{undesirable}|x \end{cases}\]4. Comparison among alignment approaches
Recently, several interesting comparison study are released for those alignment approaches.
A huggingface blog compares the current mainstream methods including DPO, IPO, and KTO using MT Bench score. The main takeaway is DPO and IPO can achieve comparable results, outperforming KTO in a paired preference setting, while KTO remains an interesting development as KTO can be applied to any dataset where responses are rated positively or negatively. However, given the KTO’s goal as maximizing human utility, I think MT Bench score as evaluation is mis-aligned at some level.
Another comprehesive study on PPO and DPO makes argument on the fundamental limitations of DPO including sensitivity to the distribution shift between the base model outputs and preference data and failure in improving the performance on challenging tasks. Another takeaway is the key factors for robust PPO training, including advantage normalization, large batch size, and updating the parameters of the reference model with an exponential moving average.
5. Miscellaneous
From the aspect of building a domain-specfic LLM product, there are some other interesting ideas in aligning user’s preference with the LLM.
One bottleneck is the exploration of LLM completion style. As mentioned in the very beginning, the user may expect stylish result from LLM while pre-trained LLMs trends to stay in a “safe zone” and overexplain common ideas. In addition to supervised fine-tuning of LLMs, optimizing the prompts automatically can be another practical solution. A LLM-based reward model can be created at (additional) prompt optimization step to align the LM completions to the human preference without fine-tuning the LLM. Some studies were made including Black-Box Prompt Optimization (BPO) and PRompt Optimization in Multi-Step Tasks (PROMST)
[1]. Training language models to follow instructions with human feedback
[2]. Direct Preference Optimization: Your Language Model is Secretly a Reward Model
[3]. KTO: Model Alignment as Prospect Theoretic Optimization
[4]. Preference Tuning LLMs with Direct Preference Optimization Methods
[5].Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study